
I took part of the Deep Learing with Pytorch challenge sponsored by Facebook the last months and I had the chance to learn from two amazing Nanodegrees at Udacity, the first is the Deep Learning Nanodegree and the second is the Deep Reinforcement Learning Nanodegree which I loved from the beginning, the content is just fascinating. Today I will try to explain reinforcement learning through a simple example.
We will start with the story of Agent-S, someone that never went to the beach before, one day he was put into the center of the ocean, he doesn’t have any prior knowledge of how to swim, but he is scary and surely will try to survive, so he starts drowning and can’t breathe anymore because of the water, so he randomly starts moving his hands up and down and got his head outside of the water and can now breathe again, he starts drawing again just after stopping his moves so this time he moves his hands and feet at the same time and realized that he got higher and was able to breathe more quickly than the first time when he moved his hands only. Agent-S was able to learn how to swim just by interacting with the environment, basically, he was performing actions (move hands, move feet, stay) while being in different states (underwater, above water) and was getting feedback from the environment on how good his actions were (able to breathe or not), next we will try to go from this analogy to explain reinforcement learning.
Reinforcement learning
Wikipedia defines RL as an area of machine learning concerned with how agents ought to take actions in an environment so as to maximize some notion of cumulative reward. Let’s demystify some of the terms here. The agent is just the party responsible of taking decisions on which action to perform next (it is Agent-S learning to swim in our example, it may be a self driving car or a simple software able to play chess as well), this agent has a certain level of interaction with the environment, in our example, Agent-S is in the middle of the ocean and can act on the environment by moving his arms and feet and can know the position he is in (underwater or not), we call actions the set of possible moves the agent can make and states the set of possible situations the agent can be in with respect to the environment. Now when the agent acts on the environment (like moving hands) he gets a certain feedback about how well he is doing so he can know if the action he just did was a good choice in the state he was in (getting outside the water is a good sign that the last action was a good choice), we call that feedback a reward, and the mission of the agent (should he choose to accept it) would be to maximize the rewards he gets over time which is called cumulative reward, in our example, Agent-S will try to keep his head outside of the water as much as he can so that he can breathe (getting the maximum cumulative rewards instead of being underwater and incapable of breathing).
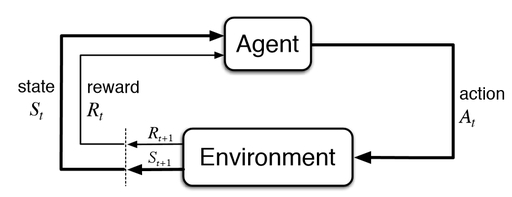
To be able to learn to maximize the cumulative reward, the agent will need to interact with the environment for a period of time exploring possible actions and their associated rewards (being in state St, make action At and get the reward Rt+1 and next state St+1), after enough interactions he can build the necessary knowledge to take the best possible action in the situation he would be in, this knowledge he builds is what we call a policy. A policy is what tells the agent while being in state S to choose a certain action A. Okay, but how does the agent learn the policy?
The Learning Phase
Now that we learned about the basics of RL, let’s build some intuition on how RL agents learn. We said that an agent being in state S must be able to choose from the set of available actions the one that will maximize its cumulative reward, let’s say the agent is at state St and he has 3 available actions A1, A2 and A3, with their respective cumulative rewards as -10, 2, and 6, the agent will basically choose the third one as it’s the best reward he can get, okay, but from where did these numbers come from? in a simple problem when we have a discrete set of states and actions, we can build what we call a Q-table, it’s a table with states as rows and actions as columns.
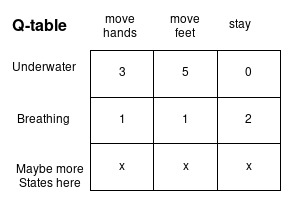
The cell for state S and action A is the cumulative reward the agent will get if starting at state S and choosing the action A, so now when we are at state S we can choose the best action that will maximize the rewards. I will not detail how the Q-table is computed, however, you already got an intuition about that, it’s through experimentation with the environment and exploration of different actions in different states, some algorithms that can be used to build the Q-table are Monte Carlo Control and Sarsa.
What’s next?
It’s true that the method that we described here can be used to solve a panoply of problems, however, Q-tables are limited in term of dimensions, you can’t build a Q-table for a problem that have an infinite set of states or actions, like have a state represented as continuous value between -10 and 10. To solve this issue we may use function estimation: a way of finding a function F that can estimate the cumulative reward from a given state and action, if you are familiar with deep learning then you might already smelt neural networks here, this is actually where Deep RL begins.
Conclusion
I hope you have enjoyed this quick and simple introduction to reinforcement learning, if you want to read about RL use cases, then I suggest to start with AlphaGo, the first computer program to defeat a professional human Go player.
comments powered by Disqus